History:Next Generation Schema/History
The Next Generation Schema (often called NGS, sometimes referred to as NadelnderBambus) is a term describing a future goal of development on the MusicBrainz database schema as well as connected interface and client changes. This page here collects and combines several older proposals, the main work on a comprehensive proposal was started in October 2005 though. The current state is mostly based on the results of the MusicBrainzSummit7.
Introduction
This page provides quite a lot of introductory material on the Next Generation Schema, but please note that we are still in the planning and collaborative brainstorming phase, so lots of things can still change. Indeed MusicBrainz currently has not enough developer time to implement this in one go. It is much more likely that MusicBrainz will move towards NGS in small incremental steps. Please see Robert's Blogpost about the future directions of MusicBrainz for more details.
The most up to date documentation of our current efforts in developing a new data model is (to be) kept in ObjectModel. And in a recent thread DonRedman was forced to present a /UsageCase for NGS. Also see the other related pages linked below.
Current Problems
There are several problems which lead to the ideas for this proposal:
Linking
When the AdvancedRelationshipTypes were developed, we came across several linking problems due to the fact that some types are not really about tracks, releases or artists as we define them in MusicBrainz but still have to use them.
For example you say "artist x composed track y" although they did not compose the released track but the song in general which may have a lot of track entities stored in the database. So you have to either link to all of them or just to the earliest one - which you sometimes cannot identify. Similar with the CoverRelationshipType: you want to say "song x is a cover of song y" but can only say "track x is a cover of track y" and there may be hundreds of releases of the song.
For artists and albums it is not so obvious but the same problems exist, too. Albums are released in many editions but the performers normally are the same for all of them so you may not want to link them to all releases in the database. But sometimes albums are re-recorded and then you want to! Or more likely: a newer release has the same performers but it has a different cover. So sometimes you want to link the cover designer to all releases, sometimes not.
Artists can perform under different performance names but you would want to have the most general data linked everywhere (like a Wikipedia page about a person) - but not always: perhaps you just want to express that a person only used one performance name when being member of a certain group.
Combining release entries
Releases are scattered loosely over the artist discography pages at the moment. Different releases of an album can't be related as well as multiple discs of a release. There's lots of uncertainty about how to handle box set releases which just combine several singles or albums that were released separately before: Should they be added as "duplicates" when they have the same tracklistings as the originals? Should they have the original release type or are they compilations? How can one say that they belong to the box set release but are also related to the original releases?
The shortcomings of the current database schema influence our style concepts a lot: we are scared of allowing duplication of releases with identical tracklists (remasters, releases under different titles like box sets, etc.) because that would clutter up the artist pages even more as we cannot group and relate them easily.
Aliases
One and the same artist often appears under a (slightly) different name on the cover of a release. In some case we keep those separate, in some we just add an alias to the artist. But it is not yet possible to say on which release an alias was used.
Internationalisation
This only concerns internationalisation of the data. The most prominent example is Пётр Ильич Чайковский - or in English better known as Pyotr Ilyich Tchaikovsky. Since he was from Russia, we keep his name in his native script. But people want to tag their data with the name Pyotr Ilyich Tchaikovsky if that's written on their releases. And releases from other countries may use other transliterations again.
The same with release and track titles: we store transliterations of releases as VirtualDuplicateReleases at the moment which looks like they were released like that - and we can't even relate them to the real releases.
Different aspects
This is a generalisation of the two points above.
We have users who would like MusicBrainz to be a general discography, that is they want to see they main albums an artist released and we have people who care about every single release that was made from an album. We have users who care about the songs in general and like the titles to be consistent and we have users who prefer what is printed on the releases, even if that isn't consistent. We want to express what artists really have done on a release and we want to express how they are credited on releases.
Some people only care about the tagging aspects of MusicBrainz, some see it as a music facts database.
The Concepts
To handle all these problems described above, different concepts have been developed.
Aspect separation: What it is and what it says
So far, the proposal handles two different aspects:
- The conceptual aspect describes "what it is", it says what an artist really has done, what concepts lie behind their work and what things are called in general. This reflects in several grouping objects which hold more general data and can be used for linking to just one object (example: a song) where before you had to link to several (tracks).
- The reality aspect describes "what it says", so what something is called in reality or how someone is credited in reality (on a release you can hold in your hand). The objects of this aspect hold data that immediately reflects the reality.
The user can chose which data they prefer themselves then (for example: for tagging they would do this by means of TaggerScript).
Grouping
To allow more general as well as exact linking, the objects are grouped together on several layers by grouping objects. Some AdvancedRelationshipTypes may only be allowed for one of those layers, some for several. Apart from AdvancedRelationships, the linking between those objects is (nearly) plain hierarchical: One grouping objects contains several sub objects which can contain several sub objects again. Actually it is a hierarchy from three sides: the song group, the album group and the artist group.
At the top of the hierarchy in the song group is the composition, which can have several recordings, which can have several mixes, then masters, then tracks. Compositions, recordings, mixes and masters belong to the conceptual aspect and therefore contain general data and are linked to an artist with AdvancedRelationships.
The album group starts with the album object (conceptual aspect), which can have several releases, which can contain several mediums, which list several tracks (reality aspect).
The artist group is a bit different and described in the next section.
The release artist concept
At the moment, artists are linked directly to releases and tracks immediately. The idea is to put an entity between them: the release artist. This nicely separates the concept (the artist) and reality aspects (the release artist). The release artist is not a full artist object, just a label representing the artist name as printed on a release. That way you can say "Пётр Ильич Чайковский is written Pyotr Ilyich Tchaikovsky on release XYZ" - and can tag your files like that if you want! Or: "Red Hot Chili Peppers released Freaky Style as The Red Hot Chili Peppers".
This is nearly like the current ArtistAliases. Indeed it will use them but add some more features like attributes (is transliteration/typo/variant/...) and the linking to releases and tracks. And a release artist can also be related to an artist but not to any release - just like an alias now.
But it can do one more thing: a release artist can also be related to several artists. This is to solve the famous SG5 disaster: a collaboration of two (or more) primary artists will be nothing but a release artist related to both (all) of them.
Grouping titles, part titles
Current plans also include two special objects which can be linked to track title objects: one for grouping titles and one for part/sub titles. That way we can easily render covers such as this - tracks 1-7 have the group title "A Flash Before My Eyes" and some of them also have titled parts. Note that this corresponds to the ID3v2 specification which includes a 'Content group description' frame and a 'Subtitle/Description refinement' frame.
Needles: transliterated titles
This is still very open in the current proposal. One idea for transliterations of titles is to attach a chain of alternate titles (combined with a lang/script descriptor) to every title object. Those attached titles are sillily called needles. Though since this produces a problem with the release artist linking (you cannot say which release artist belongs to which transliterated title) we weren't sure whether this is a good idea or not on MusicBrainzSummit7, so the bamboos lost their needles again (if someone ever wondered ;)).
Unsolved problems
There are some problems that are not solved with the current proposal. This is either because they are very rare cases and changing the schema to include them would be exaggeration - because there will always be someone finding strange cases which can't be represented even after we implemented the new schema. Or because including them would make the data model too complex and unmanageable.
Although box sets were one of the first problems that were tried to be solved when ReleaseGroups was written, there is still an aspect of them that the current proposal cannot cover: mediums can only belong to one release. So you cannot say that a disc is both an original album and part of a box set, you can only duplicate it. This is because a concept which would allow sharing objects would make both the data model and the data way too complex, so a plain hierarchical concept was preferred.
- More problems?
Steps Towards NGS
Development steps
Of course the most important step is to decide for one data model and construct the database schema for it. But this is not most of the work - there is a lot of work related to it: the web interface needs a complete rewrite, the moderation system should/could be updated, the data export and the client side need to be rewritten. This will all take very long and if it's all done in one release, people won't see any development for a long time and probably complain.
Therefore changes on the schema could be done in several steps. Those steps would mostly be oriented towards the three parts of the model: the artist group, the album group and the song group (also called the three bamboos where artist group == diagonal bamboo, album group == vertical bamboo and track group == horizontal bamboo). It is likely that either the diagonal or the vertical bamboo is implemented at first, the horizontal bamboo at last.
Migrating the data
Importing the data into a new schema will be a bit tricky. Of course one could just copy the entities to the corresponding places in the new schema (where possible...) but that would involve a lot of moderating work.
There are two basic ideas:
- Nearly every track creates its own super groups (master, mix, recording, composition) but for some it tries to guess which could belong together (same titles under one artist -> same common composition). Nearly every release is converted to a medium and creates its own release and album super group - but for some of them it tries to guess too (same release title but "(disc ...)" appended -> same release). After that moderators go and merge super groups to their knowledge.
- Or: the copied objects don't have to have super groups. Only guess them for some and don't create them for the others.
The first variant would cause a lot of merging so either a lot of MBIDs of the super groups are lost or - if we implement an ID-Alias system - IDs would have lots of aliases.
Automatic guessing of super groups would produce some failure but work fine to a certain extent. There is one important set of data though that can carelessly be used for creating super groups: AdvancedRelationships. If a track has a composer linked, then a composition group can be created for it and the relationship can link to it instead. If there is a relationship "track x is the earliest version of track y" then a common composition group can be created for both and different recording groups added to it. If there is a relationship "track x is a remix of track y" then they can even share the same recording object and only need different mix and master super groups. There are a lot more examples like those so you can see, AdvancedRelationships are the most important base for data migration and extensive linking now can help reducing the moderation effort after NGS has been implemented.
Necessary and Possible Style Guideline Changes
Most of the concepts for NGS aim at and require style guideline changes, some allow for them. Of course the following is controversial now but it is necessary to consider all of it carefully.
Consistent original data contra cover data
The goal of aspect separation is to allow for both data as it is printed on releases and for consistent data. So since both can be stored and accessed by tagger users, we need to redefine to what degree data on the reality aspect side needs to be corrected.
An example: it says Metropolis-Part I "The Miracle and the Sleeper" on Dream Theater's studio album Images and Words, Metropolis on the live album Once in a LIVEtime and Metropolis Pt.1 on the live album Live Scenes From New York - all for the same song! Current consistency rules say to use ConsistentOriginalData and give them all the same title as on the studio album. The new schema would store the consistent title in the composition object and allow the track titles to be different.
But to which extend would we follow cover titles then? Would we allow typos or even mislabeled tracks as Discogs sometimes does?
Release artists
If we can use release artists to link artist aliases to releases then we have to redefine when to use that and when to use separate artists (do we have a definition for that now?). Then it needs a good definition for when to create a new artist for a collaboration and when to use a release artist linked to several artists. This will bring up SG5 discussions up again of course.
Those two points also lead to the next one:
Credited artists
People don't like " (feat. ...)" in their track titles and want to replace it with AdvancedRelationships. But actually this nicely separates the two aspects: the relationships state what the featured artist actually has done so it is part of the concept aspect. "feat." in the track title is a credit on the reality aspect side and can mean anything - but it actually isn't important what it means because that's not what this aspect is to describe. Therefore we could go nearer to the cover data and even allow "(Duet with ...)" or similar notations. And we can even freely use the release artist field for lots of things: if the cover says "Artist X presents Artist Y feat. Artist Z - Track Title" then we could just do that without creating bogus artists.
Of course classical music is also affected by this. The composers of a work are linked on the concept aspect side. The credited artist can be whatever the cover says and tagger users can use what they prefer.
Release replication
Since the current proposal uses a hierarchical instead of a sharing system to reduce complexity, a lot of data has to be replicated. This mostly affects releases and mediums. At the moment we store different releases as one if they have the same tracklist. Since they will be grouped in NGS, we could replicate data for different medium releases, remasters, reissues under a different EAN and simple rereleases on different dates. To which extent we do that is to be clarified.
Edition titles
If we group different releases under an abstract album object which holds a general title, then the releases can store different titles if they are different on the cover. You might think this does not happen very often, but it does: many releases have edition titles like "special edition", "limited edition" and so on. It has always been controversial if those should be put in the release title or not, if they are comparable to version names of songs, if they should have their own field. At least with NGS, people can use what they prefer again.
New storage fields -> New guidelines
The next schema will contain a lot more text fields to store data in. In general, more text fields of course mean more guidelines for the allowed content. But it will also mean we can get rid of those guidelines that only exist because we don't have separate text fields yet, like SubTitleStyle for tracks or DiscNumberStyle.
We haven't decided for all the attributes and text fields yet but it is likely that every object will have one. Just think about mix objects. Will they contain the whole title + the mix title in parentheses or just the mix title? What about recording objects? Will they have a text field where you can write something like "live, 1999-07-08: Paris, France" into or does it need extra attributes for all that?
Further Information
- In ObjectModel we are analysing the problems of the current schema and try to find a new set of objects and relationships between them.
- AspectModel describes the different aspects of the world of music we have to deal with and in what different ways a user might want to look at the data.
- Later the ideas collected on those pages will lead to a concrete DatabaseModel, plans for interface changes and changes for the clients.
More recent proposals that influenced the current state:
- AlbumRework (covering ReleaseTypeRestructuringProposal, ReleaseDataSet, ReleaseRegionStyle)
- TrackGrouping
- AdvancedEntity (for creating new entity types like the ones we already have (artists, albums, tracks, URLs))
- GettingRidOfFeaturingArtistStyle (for support of multiple artists of one track/album or alternatives)
- DisentangleInterfacesFromSchema asks what a schema change can and should do, and more importantly what it should not do.
- LukasLalinsky/NGS (simplified proposal for implementation)
Previous documents addressing those changes are (some only of historical interest):
- SchemaVersion2 (very early proposal from late 2001)
- BoxSet (addressing problems with grouping albums in boxes)
- ReleaseGroups (the proposal on which AlbumRework is mostly based on)
- ReleaseHandlingPhilosophy (abandoned by the author in favour of AlbumRework)
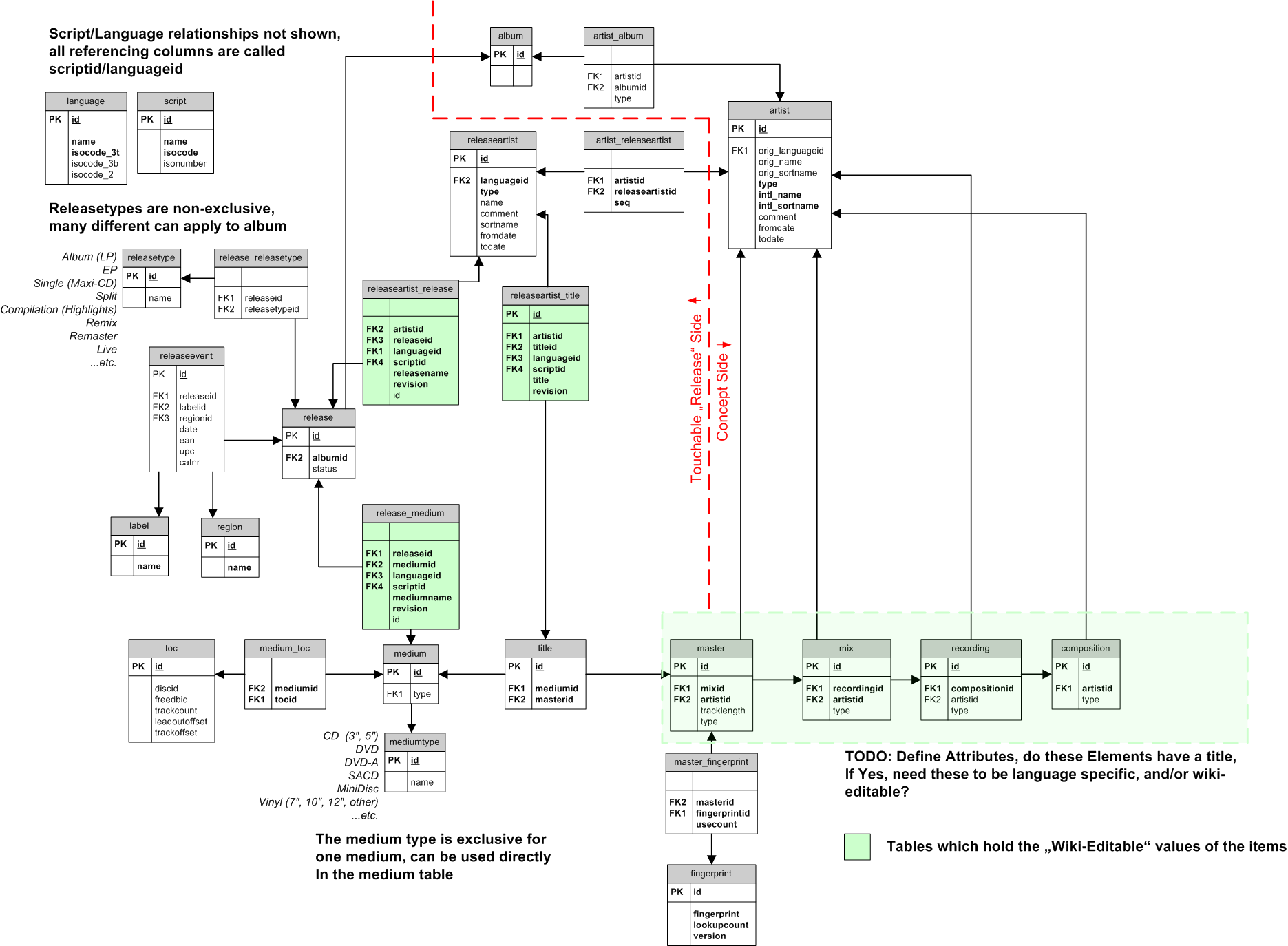
A first experimental draft version of the new DB schema design is below: 
or take a look at the full size version.
{kind=link}