User:Davitof/Classical Future: Difference between revisions
m (2 revision(s)) |
m (10 revision(s)) |
(No difference)
| |
Revision as of 08:42, 15 March 2009
I will try to summarize here the ideas that were suggested in the three "Classical" threads I started ("Data structure for classical", "Data input in classical", "Searching in classical music") plus a few other threads such as "Classical Style Guide: Using Bach's work no. as prefix or suffix". I may have forgotten some items; if I did, please tell me. Please feel free to add comments to this page, although I think that posting a note on one of the MB groups to warn other classical-minded MB users would be a good idea.
First of all, I want to specify this is NOT even a structure suggestion, just a raw presentation of suggestions which were made in those threads. I did try to apply those suggestions to what I thought I understood of MB's database, but I probably did at least a few mistakes.
I tried to summarize these discussions in a diagram. This diagram does not pretend to be a database model. It contains mainly elements which are not already in the current MB database. Anyway, the tool I used was not adequate (but it was not designed for this task). If someone can suggest a better suited free tool for this work...
If someone wants to edit the diagram himself (after all, this is a wiki!) I can provide the source of the diagram. I used a special version of FreeMind, an open source mind mapper.
Terminology: Despite the term used in the MB wiki, instead of "composition", I used work, only because it is more generic ("work" can be used for text-only recordings and I always felt a little awkward when using composition for an opera: would I mean the full work or just the music?). Furthermore, posters did tend to use "work" spontaneously instead of "composition".
I tried to use the ObjectModel to include the information items that were identified in these threads. ObjectModel is supposed to be outdated, or so says the very first line of the page. For lack of better documentation, I proceeded as if it was up-to-date. If one of the elements I use is outdated, could someone knowledgeable tell me so?
Here is a general and simplified view of the diagram:

In this much more detailed and interesting version of the diagram,
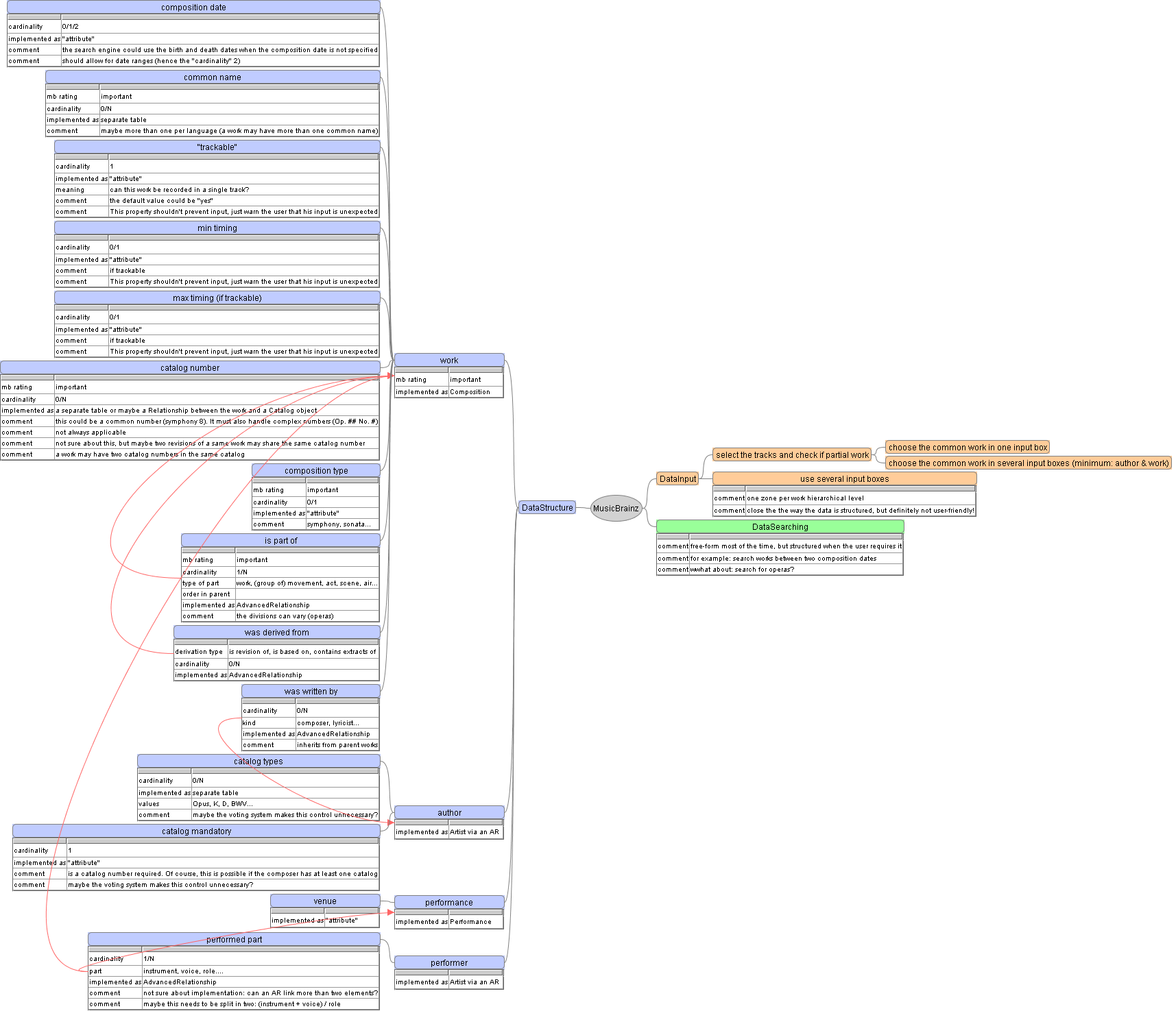{kind=link}
- "cardinality" stands for the number of occurrences of the element in the father element. Since the modifications are strictly hierarchical, there is no need for using the full meaning of cardinality, anyway.
- "implemented as" tries to suggest how the information should be stored. This is usually simply deduced from the cardinality.
- "mb rating" can only "important". This shows the elements which could not be avoided
- the red arrows show the second element of an AR
.
Comments
Here are a few further comments (not necessarily part of he previous threads, but which have occurred to me while writing this):
I was the only one to defend the idea of min/max timings.
Although data handling seems more complicated for classical than for other kinds of music, the resulting interface should be simple. Ideally, it should be simple enough to avoid the need for a complex help system. It is possible that the user interface for classical will be different from the UI for other kinds of music, but if we want to stay simple, this should be avoided too. As an afterthought, the only elements in the diagram which would probably not apply to non-classical music are those related to catalogs. Seen this way, the diagram mainly emphasizes what is more important for classical than for other kinds of music.
We may decide to handle the notion of work revision, (many classical works have had several editions with substantial changes between editions). I am not sure this would be a good idea. Or rather, the user should be able to relate a track to a generic version of the work because sometimes the user won't be able to know which particular edition of the work was used for the performance.
Several ways to input data have been suggested, but the simplest seems to be:
- select the tracks which are to be titled, give the composer (if the catalog is not enough), a catalog reference or a common name, and let MB suggest the tracks names. This would probably work nicely with simple works, but it has a few database implications. I already said we would need to have a work type. IMO this would make searching easier, because a work would be classified under an abstract work type rather than under for example the english work "symphony" or the french "symphonie". Now, let's say a user wants to input Beethoven's 6th symphony. If he uses the common name MB should be able to retrieve the correct work, whether the user typed "Pastoral" or "Pastorale" or something else. Technically, this means that the common name is not stored in the work but in a separate table (actually, each work could have at least as many common names as there are human languages!). So the search module must be smart enough to see that "Pastoral" is a common name and choose the search path accordingly. And what about opera airs? As a Google user, I would probably try something like "Figaro sapete", hoping for "Voi che sapete". This time, MB should guess that "Figaro" is from the opera title (almost top level) while "sapete" is from the air's title (two levels lower, the user having said nothing of the act).
Input could be made easier if MB could offer a kind of remanence. Once I have chosen a movement from a work, very often the next track I will be entering is the next movement from the same work. So remanence would make input much much easier.